안녕하세요?
Istio in Action 책을 공부하면서 내용을 조금씩 정리해보려고 합니다.
6장은 복원력: 애플리케이션 네트워킹 문제 해결하기 입니다.
실습 환경 준비
- MacOS, OrbStack으로 Container 구동
- Kind, k8s 1.33.1
- istioctl 1.27.0
curl -L https://istio.io/downloadIstio | sh -
istioctl install --set profile=demo -y
|\
| \
| \
| \
/|| \
/ || \
/ || \
/ || \
/ || \
/ || \
/______||__________\
____________________
\__ _____/
\_____/
WARNING: Istio is being upgraded from 1.13.0 to 1.27.0.
Running this command will overwrite it; use revisions to upgrade alongside the existing version.
Before upgrading, you may wish to use 'istioctl x precheck' to check for upgrade warnings.
✔ Istio core installed ⛵️
✔ Istiod installed 🧠
✔ Egress gateways installed 🛫
✔ Ingress gateways installed 🛬
✔ Installation complete6.1 애플리케이션에 복원력 구축하기
- 마이크로서비스는 복원력을 최우선으로 고려해 구축해야 함
- 애플리케이션이 장애를 예상해 요청을 처리할 때 자동으로 복원을 시도하거나 대체 경로로 돌아갈 수 있도록 구축해야 한다.
- 재시도, 타임아웃, 서킷 브레이킹
6.1.1 애플리케이션 라이브러리에 복원력 구축하기
이런 류의 문제를 해결하는 프레임워크들
- Finagle : 트위터 오픈소스
- 타임아웃, 재시도, 서킷 브레이킹
- Hystrix, Ribbon : 넷플릭스
하지만 프레임워크는 언어, 인프라 조합마다 구현방식이 상이하여 부담이 된다.
6.1.2 이스티오로 이런 문제 해결하기
이스티오 프록시는 애플리케이션 수준 요청과 메시지를 이해하므로 프록시 안에서 복원기능을 구현할 수 있다.
- 클라이언트 측 로드밸런싱
- 지역 인식 로드밸런싱
- 타임아웃 및 재시도
- 서킷 브레이킹
6.1.3 분산형 복원력 구현
- 이스티오를 사용하면 애플리케이션 요청이 통과하는 데이터 플레인 프록시가 애플리케이션 인스턴스와 같은 위치에 있다.
- 중앙집중식 게이트웨이가 필요하지 않다.
6.2 클라이언트 측 로드밸런싱
- 클라이언트 측 로드밸런싱 :
- 엔드포인트 간에 요청을 최적으로 분산시키기 위해 클라이언트에게 서비스에서 사용할 수 있는 여러 엔드포인트를 알려주고 클라이언트가 특정 로드밸런싱 알고리즘을 선택하게 하는 방식
- 중앙집중식 로드 밸런싱에 의존할 필요성이 줄어듬
- 클라이언트가 여러 홉을 거칠 필요없이 특정 엔드포인트로 직접적이면서 의도적으로 요청을 보낼 수 있음
- 이스티오는 서비스간 통신시 클라이언트측 프록시에 올바른 최신 정보를 제공함
- DestinationRule 리소스로 클라이언트가 어떤 로드 밸런싱 알고리즘을 사용할 지 설정 가능
- 라운드 로빈
- 랜덤
- 가중치를 적용한 최소 요청 알고리즘이 가능
6.2.1 클라이언트 측 로드밸런싱 시작하기
k apply -f ch6/simple-backend.yaml
k apply -f ch6/simple-web.yaml
k apply -f ch6/simple-web-gateway.yaml
위 배포한 서비스들에 대해 서비스를 호출하는 모든 클라이언트의 로드밸런싱을 ROUND_ROBIN으로 설정할 수 있다.
DestinationRule은 특정 목적지를 호출하는 메시 내 클라이언트들에 정책을 지정한다.
k apply -f ch6/simple-backend-dr-rr.yaml apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: ROUND_ROBINk get pod
NAME READY STATUS RESTARTS AGE
simple-backend-1-75695cfbcc-5rll5 1/1 Running 0 5m8s
simple-backend-2-fff7fcc45-bg8gl 1/1 Running 0 5m8s
simple-backend-2-fff7fcc45-xpz48 1/1 Running 0 5m8s
simple-web-85d57c8486-x8hxw 1/1 Running 0 5m
simple-web은 simple-backend를 호출한다.
아래 예시 서비스집합에서는 호출 체인을 보여주는 JSON 응답을 받는다.
simple-backend-1에서 온 응답 메시지 Hello를 보다가도 몇 번 더 반복하면 2에서도 반응을 받는다.
curl http://192.168.97.2:31733 -H "Host: simple-web.istioinaction.io"
{
"name": "simple-web",
"uri": "/",
"type": "HTTP",
"ip_addresses": [
"10.244.0.19"
],
"start_time": "2025-09-07T10:44:48.725674",
"end_time": "2025-09-07T10:44:48.951589",
"duration": "225.879ms",
"body": "Hello from simple-web!!!",
"upstream_calls": [
{
"name": "simple-backend",
"uri": "http://simple-backend:80/",
"type": "HTTP",
"ip_addresses": [
"10.244.0.17"
],
"start_time": "2025-09-07T10:44:48.788603",
"end_time": "2025-09-07T10:44:48.939416",
"duration": "150.815ms",
"headers": {
"Content-Length": "279",
"Content-Type": "text/plain; charset=utf-8",
"Date": "Sun, 07 Sep 2025 10:44:48 GMT"
},
"body": "Hello from simple-backend-2",
"code": 200
}
],
"code": 200
}for i in {1..10}; do \
curl http://192.168.97.2:31733 -H "Host: simple-web.istioinaction.io" | jq ".upstream_calls[0].body"; printf "\n"; donefor i in {1..10}; do \
curl http://192.168.97.2:31733 -H "Host: simple-web.istioinaction.io" | jq ".upstream_calls[0].body"; printf "\n"; done
"Hello from simple-backend-2"
"Hello from simple-backend-1"
"Hello from simple-backend-1"
"Hello from simple-backend-1"
"Hello from simple-backend-2"
"Hello from simple-backend-2"
"Hello from simple-backend-1"
"Hello from simple-backend-2"
"Hello from simple-backend-2"
"Hello from simple-backend-1"
효과적으로 엔드포인트 분산이 되는 것을 볼 수 있다.
이게 가능한 이유는 simple-web과 함께 배포된 서비스 프록시가 모든 simple-backend엔드포인트를 알고 있고 기본 알고리즘을 사용해 요청을 받을 엔드포인트를 결정하고 있기 때문이다.
6.2.2 시나리오 설정하기
- 현실 환경에서는 서비스가 요청을 처리하는 데 시간이 걸린다.
- 요청 크기
- 처리 복잡도
- 데이터베이스 사용량
- 시간이 걸리는 다른 서비스 호출
- 예기지 못한, 모든 작업을 멈추는 (stop-the-world) 가비지 컬렉션
- 리소스 경합(CPU, 네트워크 등)
- 네트워크 혼잡
- Fortio라는 CLI 부하생성 도구를 사용해서 클라이언트 측 로드 밸런싱 차이를 관찰
- github.com/fortio/fortio
brew install fortio
- github.com/fortio/fortio
6.2.3 다양한 클라이언트 측 로드 밸런싱 전략 테스트하기
- fortio를 사용해서 60초 동안 10개의 커넥션을 통해 초당 1,000개의 요청 보내기
k apply -f ch6/simple-backend-delayed.yamlfortio server
# localhost:8080/fortio 접근
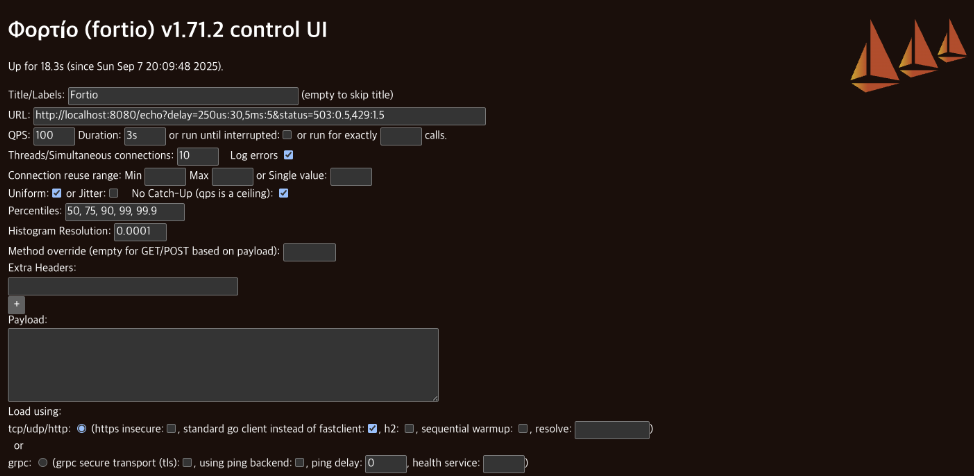
- title: roundrobin
- url: http://192.168.97.2:31733
- qps: 1000
- duration: 60s
- threads: 10
- jitter: 체크
- headers:



All done 59780 calls 0.127 ms avg, 996.2 qps
이제 로드밸런싱 알고리즘을 RANDOM으로 변경하고 다시 테스트하기
k apply -f ch6/simple-backend-dr-random.yaml
6.2.4 다양한 로드밸런싱 알고리즘 이해하기
- 라운드로빈은 엔드포인트에 차례대로 요청을 전달한다.
- 랜덤은 엔드포인트를 무작위로 균일하게 고른다.
- 최소 커넥션 로드밸런서는 특정 엔드포인트의 지연 시간을 고려한다.
- 요청을 엔드포인트로 보낼 때 대기열 깊이 queue depth를 살펴 활성 요청개수를 파악하고, 활성 요청이 가작 적은 엔드포인트를 고른다.
6.3 지역 인식 로드 밸런싱
- 이스티오같은 서비스메시는 서비스 토폴로지를 이해해서 서비스와 피어 서비스의 위치같은 휴리스틱을 바탕으로 라우팅과 로드 밸런싱을 자동으로 결정할 수 있다.
- 예를들어 워크로드의 위치에 따라 루트에 가중치를 부여하고 라우팅 결정을 내릴 수 있다.
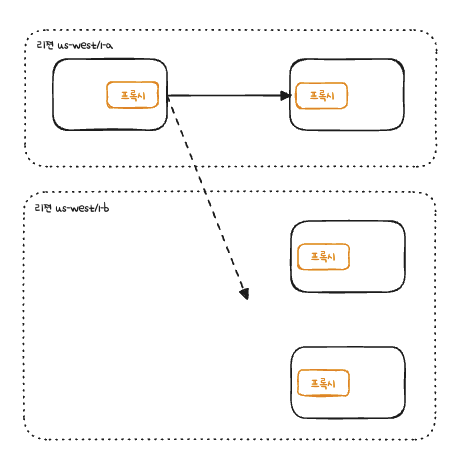
6.3.1 지역 인식 로드 밸런싱 실습
- 쿠버네티스에 배포시 리젼과 영역 정보를 노드 레이블에 추가할 수 있다.
- 실제 Cloud에서는 Cloud service provider가 자동으로 추가하는 경우가 많다.
- 테스트용으로는 파드에 istio-locality라는 레이블을 달아볼 수 있다.
- 아래와 같이 이런 레이블을 달아준다.
- istio-locality: us-west1.us-west1-a
apiVersion: apps/v1 kind: Deployment metadata: labels: app: simple-web name: simple-web spec: replicas: 1 selector: matchLabels: app: simple-web template: metadata: labels: app: simple-web istio-locality: us-west1.us-west1-a spec: serviceAccountName: simple-web containers: - env: - name: "LISTEN_ADDR" value: "0.0.0.0:8080" - name: "UPSTREAM_URIS" value: "http://simple-backend:80/" - name: "SERVER_TYPE" value: "http" - name: "NAME" value: "simple-web" - name: "MESSAGE" value: "Hello from simple-web!!!" - name: KUBERNETES_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace image: nicholasjackson/fake-service:v0.14.1 imagePullPolicy: IfNotPresent name: simple-web ports: - containerPort: 8080 name: http protocol: TCP securityContext: privileged: false
- istio-locality: us-west1.us-west1-a
이제 us-west1-a에 있는 simple-web의 호출은 같은 영억인 us-west1-a에 배포된 simple-backend 서비스로 보낼 수 있다.
a에 있는 서비스가 실패하기 시작할때만 b에있는 서비스인 simple-backend-2로 가게된다.
대신에 지역 인식 로드밸런싱이 작동하려면 헬스체크를 설정해야 한다.
헬스 체크가 없으면 이스티오가 로드밸런싱 풀의 어느 엔드포인트가 비정상인지 알수 없다.
```yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
outlierDetection:
consecutive5xxErrors: 1
interval: 5s
baseEjectionTime: 30s
maxEjectionPercent: 100그리고 1로 가는 서비스를 오동작 상태로 만들면 된다.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
name: simple-backend-1
spec:
replicas: 1
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
istio-locality: us-west1.us-west1-a
spec:
serviceAccountName: simple-backend
containers:
- env:
- name: "LISTEN_ADDR"
value: "0.0.0.0:8080"
- name: "SERVER_TYPE"
value: "http"
- name: "NAME"
value: "simple-backend"
- name: "MESSAGE"
value: "Hello from simple-backend-1"
- name: "ERROR_TYPE"
value: "http_error"
- name: "ERROR_RATE"
value: "1"
- name: "ERROR_CODE"
value: "500"
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: nicholasjackson/fake-service:v0.14.1
imagePullPolicy: IfNotPresent
name: simple-backend
ports:
- containerPort: 8080
name: http
protocol: TCP
securityContext:
privileged: false6.4 투명한 타임아웃과 재시도
6.4.1 타임아웃
- 분산환경에서 가장 다루기 어려운 시나리오는 "지연 시간"
- 처리 속도가 느려지면 리소스를 오래 들고 있게 되고
- 서비스에는 처리해야 할 작업이 적체될 수 있고
- 연쇄 장애로 이어질 수 있다.
- 그러니 커넥션이나 요청에서 타임아웃을 구현해야 한다.
이스티오에서는 VirtualService 리소스로 요청별로 타임아웃을 지정할 수 있다.
이렇게 지정하면 메시 내 클라이언트에서 simple-backend로 향하는 호출의 타임아웃을 0.5초로 지정할 수 있다.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-backend-vs
spec:
hosts:
- simple-backend
http:
- route:
- destination:
host: simple-backend
timeout: 0.5s6.4.2 재시도
기본적으로 이스티오는 호출이 실패하면 두 번 더 시도한다.
아래 상황에서는 재시도해도 안전하다.
- 커넥션 수립 실패 connect-failure
- 스트림 거부됨 refused-stream
- 사용 불가 gRPC 상태코드 14
- 취소됨 gRPC 상태코드 1
- 재시도할 수 있는 상태 코드들 503등
이렇게 명시적으로 설정할 수도 있다.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-backend-vs
spec:
hosts:
- simple-backend
http:
- route:
- destination:
host: simple-backend
retries:
attempts: 2작동 방식
요청이 이스티오 서비스 프록시를 거쳐 흐를때, 업스트림으로 전달되는 데 실패하면 요청을 실패 failed로 표시하고 VirtualService 리소스에 정의한 최대 재시도 횟수까지 재시도한다.
재시도 횟수가 2이면 실제로는 요청이 3회까지 전달된다. (한번은 원래 요청)
재시도 사이에 이스티오는 25ms를 베이스로 재시도를 "백오프"한다. 그러니까, "기다린다".
재시도횟수를 무턱대고 설정하면 심각한 재시도 thundering herd가 발생할 수도 있기 때문에 아키텍쳐 가장자리에서는 재시도 횟수를 1회 내지 0으로 제한하고 중간 요소는 0회로 하는것이 좋다.
6.4.3 고급 재시도
이스티오 재시도 백오프 시간은 25ms이고, 재시도할 수 있는 상태코드는 HTTP 503뿐이다.
이스티오 확장 API를 사용하면 엔보이 설정에서 이 값들을 직접 바꿀 수 있다.
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: simple-backend-retry-status-codes
namespace: istioinaction
spec:
workloadSelector:
labels:
app: simple-web
configPatches:
- applyTo: HTTP_ROUTE
match:
context: SIDECAR_OUTBOUND
routeConfiguration:
vhost:
name: "simple-backend.istioinaction.svc.cluster.local:80"
patch:
operation: MERGE
value:
route:
retry_policy: <---------------- 엔보이 설정에서 직접 나옴
retry_back_off:
base_interval: 50ms <------ 기본 간격을 늘림
retriable_status_codes: <---- 재시도할 수 있는 코드를 추가
- 408
- 400
그리고 위에서 설정한 retriable-status-code를 포함하도록 retryOn필드도 업데이트해야 한다.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-backend-vs
spec:
hosts:
- simple-backend
http:
- route:
- destination:
host: simple-backend
retries:
attempts: 2
retryOn: 5xx,retriable-status-codes <------ 재시도할 수 있는 상태코드요청 헤징
요청 헤징 request hedging : 요청이 타임아웃되면 다른 호스트로도 요청을 보내 원래의 타임아웃된 요청과 경쟁 race 시키는 것.
경쟁한 요청이 성공적으로 반환되면, 그 응답을 원래 다운스트림 호출자에게 보내기.
만약 경쟁한 요청보다 원본 요청이 먼저 반환되면, 다운 스트림 호출자에게 반환.
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: simple-backend-retry-hedge
namespace: istioinaction
spec:
workloadSelector:
labels:
app: simple-web
configPatches:
- applyTo: VIRTUAL_HOST
match:
context: SIDECAR_OUTBOUND
routeConfiguration:
vhost:
name: "simple-backend.istioinaction.svc.cluster.local:80"
patch:
operation: MERGE
value:
hedge_policy:
hedge_on_per_try_timeout: true'Kubernetes' 카테고리의 다른 글
| Istio in Action 9장 - 마이크로서비스 통신 보호하기 (0) | 2025.10.12 |
|---|---|
| Istio in Action 7장 - 관찰 가능성: 서비스의 동작 이해하기 (0) | 2025.09.17 |
| Istio in Action 5장 - 트래픽 제어 : 세밀한 트래픽 라우팅 (1) | 2025.08.28 |
| Istio in Action 4장 - Istio Gateway : 클러스터로 트래픽 들이기 (0) | 2025.08.20 |
| Gateway API, AWS Gateway API Controller (0) | 2025.04.26 |