들어가며
이번에 멋진 가시다님이 운영하시는 CloudNeta 팀의 스터디에 1년만에 다시 참여하게 되었습니다.
이번 주제는 쿠버네티스 네트워크 매운맛입니다.
이 KANS (Kubernetes Advanced Network Study)의 1주차 과제로서 학습한 내용을 정리해보려고 합니다.
심화 이해를 하려고 하다보면 항상 먼 옛날에 잊혀진 기초가 발목을 잡으니
복습을 하면서 다시 한번 전체 내용을 되짚어 보겠습니다.
Container 격리를 추상적으로 이해하기
가상화와 Container 환경에 대한 도식화 한 이해
저는 멋진 널널한 개발자님의 강의 내용를 자주 보는데,
가상화에 대한 쉬운 설명이 있어서 일부 그림으로 갖고 왔습니다.
출처영상은 이곳입니다
널널한 개발자님은 아래와 같은 간단한 도식 형태로 설명을 하시는데 즉각적인 이해에 매우 도움이 됩니다.
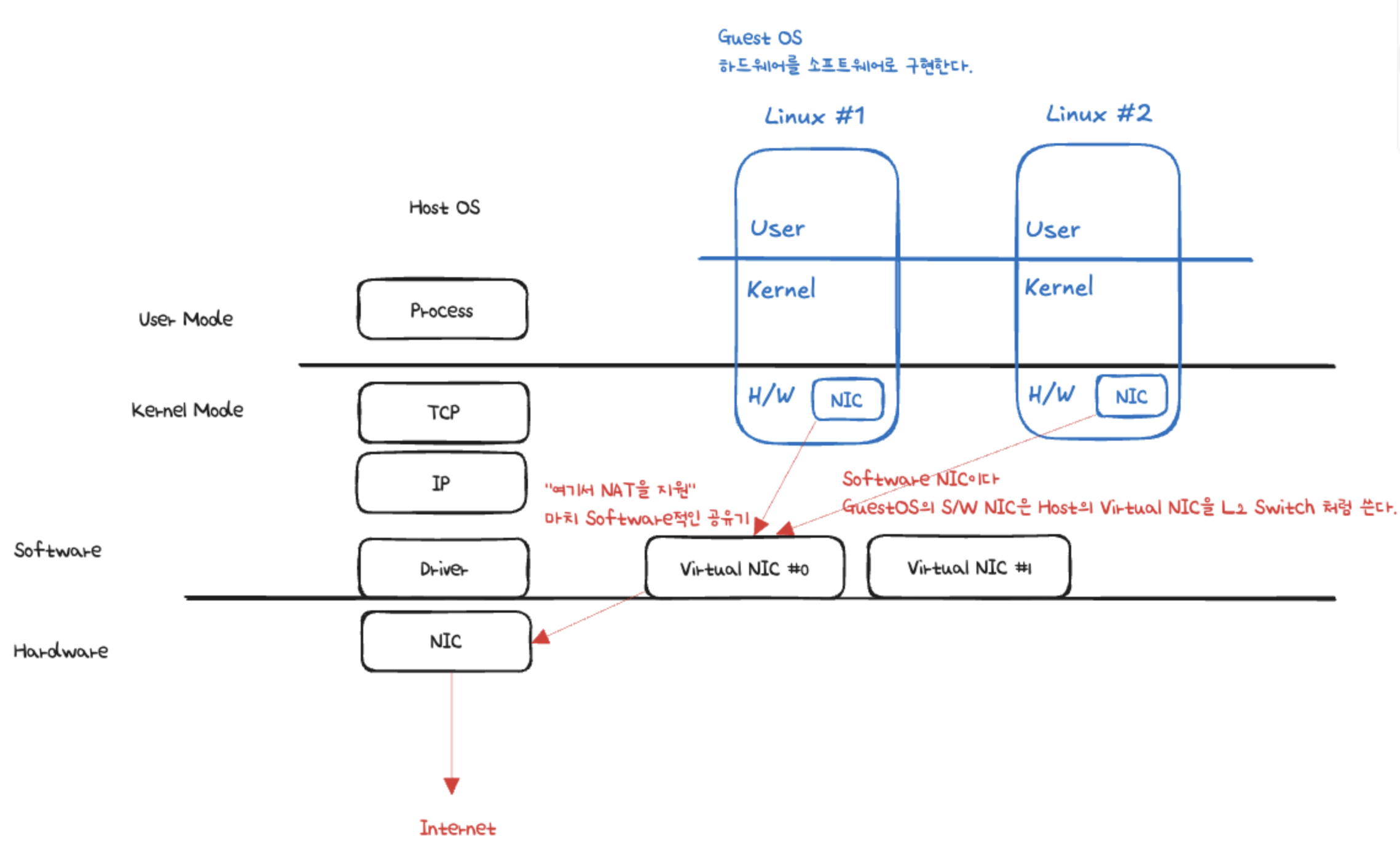
VMWare같은 일반적인 가상화 환경은 위와 같습니다.
쿠버네티스 공홈에는 Container evolution 에 대한 위와 같은 도식이 있습니다.
위 그림을 Virtualized Deployment라고 했을 때 Docker 로 대표되는 Container Runtime 이 중간 부분을 대체하게 된다고 이해했습니다.

다시 널널한 개발자님의 도식으로 돌아오면 아래와 같이 됩니다.
대신에 OS를 별도 격리 하지 않으니 호스트 OS(커널)를 공유하게 됩니다.
그리고 개별적인 User Space를 가지게 됩니다.

그래서 Container 란 무엇이고 왜 사용하나요?
Container는 격리된 환경에서 실행하는 Process입니다.
Container를 사용하면
- 애플리케이션 사용에 필요한 코드, 설정, 의존성 라이브러리, 실행 파일을 하나로 묶어서 관리할 수 있습니다.
- 격리가 되어서 Process 주변 영향이 차단됩니다.
- 자원을 개별 할당하고 사용을 보장할 수 있습니다.
그리고 이와 같이 격리를 하기위해 리눅스의 격리 기술을 사용합니다.
가상화된 공간을 생성하기 위해 리눅스 기능 pivot-root, 네임스페이스(namespace), cgroup 를 사용함으로써 프로세스 단위의 격리 환경과 리소스을 제공합니다.
그러니까 Container는 리눅스 OS 사용을 전제한다고 할 수 있을 것 같습니다.
그러면 Process는 뭔가요?
- 프로세스는 실행 중인 프로그램의 인스턴스를 의미합니다.
- OS에서 프로세스를 관리하며, 각 프로세스는 고유한 ID(PID)를 가집니다.
- 프로세스는 CPU와 메모리를 사용하는 기본 단위로, OS 커널(Cgroup)에서 각 프로세스의 자원을 관리합니다.

출처 : x.com
리눅스의 /proc 디렉터리는 커널이 동적으로 write하여 생성하는 정보를 실시간 제공합니다 :
시스템 상태, 프로세스(/proc/[PID]), HW 정보
- /proc/cpuinfo: CPU에 대한 정보가 포함되어 있습니다. CPU 모델, 코어 수, 클럭 속도 등의 정보를 확인할 수 있습니다.
- /proc/meminfo: 메모리 사용 현황을 보여줍니다. 전체 메모리, 사용 중인 메모리, 가용 메모리, 캐시 메모리 등 다양한 메모리 관련 정보를 제공합니다.
- /proc/uptime: 시스템이 부팅된 후 경과된 시간을 초 단위로 보여줍니다. 첫 번째 숫자는 총 가동 시간, 두 번째 숫자는 시스템의 유휴 시간입니다.
- /proc/loadavg: 시스템의 현재 부하 상태를 나타냅니다. 첫 번째 세 개의 숫자는 1, 5, 15분간의 시스템 부하 평균을 의미하며, 네 번째 숫자는 현재 실행 중인 프로세스와 총 프로세스 수, 마지막 숫자는 마지막으로 실행된 프로세스의 PID를 나타냅니다.
- /proc/version: 커널 버전, GCC 버전 및 컴파일된 날짜와 같은 커널의 빌드 정보를 포함합니다.
- /proc/filesystems: 커널이 인식하고 있는 파일 시스템의 목록을 보여줍니다.
- /proc/partitions: 시스템에서 인식된 파티션 정보를 제공합니다. 디스크 장치와 해당 파티션 크기 등을 확인할 수 있습니다.
- 프로세스(/proc/[PID]) 별 정보
/proc/[PID]/cmdline: 해당 프로세스를 실행할 때 사용된 명령어와 인자를 포함합니다./proc/[PID]/cwd: 프로세스의 현재 작업 디렉터리에 대한 심볼릭 링크입니다.ls -l로 확인하면 해당 프로세스가 현재 작업 중인 디렉터리를 알 수 있습니다./proc/[PID]/environ: 프로세스의 환경 변수를 나타냅니다. 각 변수는 NULL 문자로 구분됩니다./proc/[PID]/exe: 프로세스가 실행 중인 실행 파일에 대한 심볼릭 링크입니다./proc/[PID]/fd: 프로세스가 열어놓은 모든 파일 디스크립터에 대한 심볼릭 링크를 포함하는 디렉터리입니다. 이 파일들은 해당 파일 디스크립터가 가리키는 실제 파일이나 소켓 등을 참조합니다./proc/[PID]/maps: 프로세스의 메모리 맵을 나타냅니다. 메모리 영역의 시작과 끝 주소, 접근 권한, 매핑된 파일 등을 확인할 수 있습니다./proc/[PID]/stat: 프로세스의 상태 정보를 포함한 파일입니다. 이 파일에는 프로세스의 상태, CPU 사용량, 메모리 사용량, 부모 프로세스 ID, 우선순위 등의 다양한 정보가 담겨 있습니다./proc/[PID]/status: 프로세스의 상태 정보를 사람이 읽기 쉽게 정리한 파일입니다. PID, PPID(부모 PID), 메모리 사용량, CPU 사용률, 스레드 수 등을 확인할 수 있습니다.
Container 격리에 사용되는 기술들을 이해해보자
IFKakao 2022에 "이게 돼요? 도커 없이 컨테이너 만들기" 라는 세션이 있었습니다.
컨테이너와 격리의 심화 이해를 위해 해당 세션을 따라하며 실습을 진행해보았습니다.
해당 실습은 Ubuntu 22.04 에서 수행했습니다.
아래 도식은 해당 영상에서 그려주신 Container 격리 기술의 역사를 나타낸 것입니다.
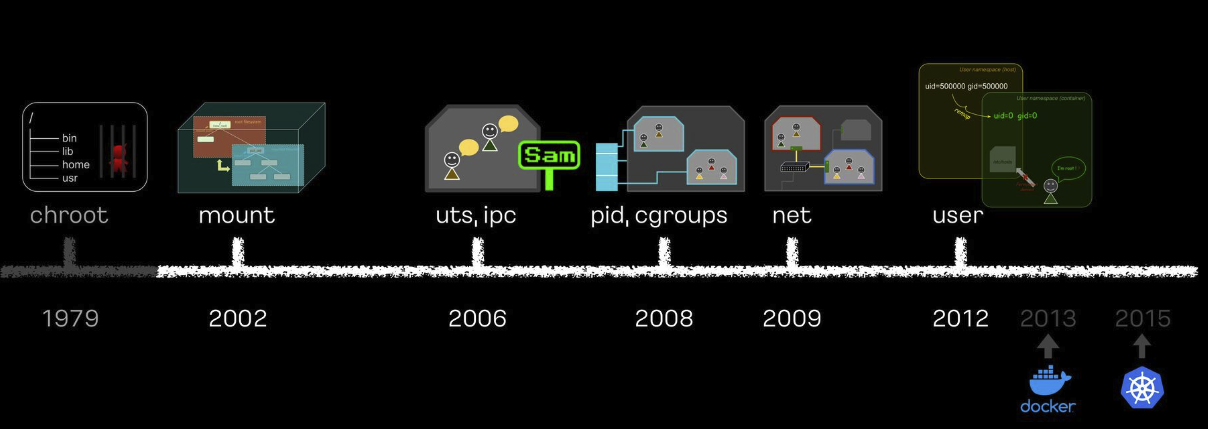
출처 : 이게 돼요? 도커 없이 컨테이너 만들기 - Speaker Deck
Container 와 Host 환경 비교
아래처럼 busybox를 띄워서 Host와 Container를 비교하는 방식입니다.
sudo docker run -it busybox - root 디렉토리 비교
root 디렉토리가 다르면 다른 시스템입니다.
# host
ls /
bin boot etc lib lib64 media opt root sbin snap sys usr
bin.usr-is-merged dev home lib.usr-is-merged lost+found mnt proc run sbin.usr-is-merged srv tmp var
# container
ls /
bin dev etc home lib lib64 proc root sys tmp usr var
- 파일시스템 비교
컨테이너의 루트 디렉토리는 파일시스템이 overlay로 보입니다.
그리고 호스트의 루트 디렉토리는 파일시스템이 dev 디바이스 경로에 있는 것으로 보입니다.
# host
df -h
Filesystem Size Used Available Use% Mounted on
overlay 47.4G 2.7G 44.6G 6% /
# container
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 48G 2.8G 45G 6% /- 프로세스 비교
호스트의 프로세스는 뭔가 많습니다.
컨테이너의 1번 프로세스는 shell 이고 2개 밖에 안보입니다.
# host
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 22568 13824 ? Ss Aug30 0:08 /usr/lib/systemd/systemd --sys
root 2 0.0 0.0 0 0 ? S Aug30 0:00 [kthreadd]
...
# container
ps aux
PID USER TIME COMMAND
1 root 0:00 sh
8 root 0:00 ps aux
- 네트워크 비교
ip link를 통해서는 물리장치 위의 link layer, 네트워크 장치들을 볼 수 있습니다.
컨테이너에서는 loop back과 ethernet 0가 보입니다.
호스트에서는 lo.. docker도 보이고 virtual ethernet도 보이고 그렇습니다.
# host
ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 02:65:f0:0e:28:ad brd ff:ff:ff:ff:ff:ff
altname enp0s5
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:07:1c:1b:46 brd ff:ff:ff:ff:ff:ff
5: veth8bfb892@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 22:94:64:d2:e9:28 brd ff:ff:ff:ff:ff:ff link-netnsid 0
9: vethddcfb0e@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether e2:f8:a4:95:26:7f brd ff:ff:ff:ff:ff:ff link-netnsid 1
# container
ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
8: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff
- 호스트 네임 비교
hostname도 다릅니다.
# host
hostname
MyServer
# container
hostname
31824e2d13e8- uid, gid 비교
컨테이너는 보안상 취약하므로 루트 권한이 아닌게 좋습니다.
컨테이너의 루트는 호스트의 루트와 같은 루트일까요?
# host
id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm),24(cdrom),27(sudo),30(dip),105(lxd)
# container
id
uid=0(root) gid=0(root) groups=0(root),10(wheel)Container 격리에 사용되는 기술 1. 파일시스템을 격리하자
Chroot
여러 사람이 이용하는 서버에서 격리된 환경을 만들기 위해서 처음 나온 아이디어는
change root라고 합니다 .
- chroot

출처 : 이게 돼요? 도커 없이 컨테이너 만들기 - Speaker Deck
chroot는 change root 의 줄임말입니다.
파일을 경로에 모으고, 경로에 가둬서 실행할 수 있습니다.
호스트에서 chroot 테스트를 아래와 같이 해볼 수 있습니다.
myroot가 제 기능을 하려면 /bin/sh 도 옮겨줘야 합니다.
이때 /bin/sh만 복사하는게 아니라 라이브러리 의존성까지 확인합니다.
아래를 확인해서 libc, lid-linux-x86-64.so.2 를 복사해줍니다.
/bin/ls도 마찬가지입니다.
ldd /bin/sh
linux-vdso.so.1 (0x00007ffdf8f7c000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007c2555800000)
/lib64/ld-linux-x86-64.so.2 (0x00007c2555ba9000)
ldd /bin/ls
linux-vdso.so.1 (0x00007ffc9d31b000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007a92a97d3000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007a92a9400000)
libpcre2-8.so.0 => /lib/x86_64-linux-gnu/libpcre2-8.so.0 (0x00007a92a9739000)
/lib64/ld-linux-x86-64.so.2 (0x00007a92a982d000)mkdir myroot -p myroot/bin
cp /bin/sh myroot/bin/
mkdir -p myroot/{lib64,lib/x86_64-linux-gnu}
cp /lib/x86_64-linux-gnu/libc.so.6 myroot/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 myroot/lib64
cp /bin/ls myroot/bin/
cp /lib/x86_64-linux-gnu/{libselinux.so.1,libc.so.6,libpcre2-8.so.0,ld-linux-x86-64.so.2} myroot/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 myroot/lib64/
myroot/
├── bin
│ ├── ls
│ └── sh
├── lib
│ └── x86_64-linux-gnu
│ ├── ld-linux-x86-64.so.2
│ ├── libc.so.6
│ ├── libpcre2-8.so.0
│ ├── libpthread.so.0
│ └── libselinux.so.1
└── lib64
└── ld-linux-x86-64.so.2
chroot myroot /bin/sh
# 이 지점에서 프롬프트가 바뀝니다.
ls
bin lib lib64
# 그리고 확인해보면 탈출이 되지 않습니다.
cd ../../../이렇게 chroot 만 있으면 컨테이너를 격리하는데 충분하지 않을까요?
chroot는 package와 격리관점에서는 필요한 부분을 갖고 있지만 탈옥이 가능하다는 단점이 있습니다.
그래서 실제로는 쓸 수가 없습니다.
Pivot_root
그래서 위 단점을 해결하기 위해 루트 파일 시스템을 pivot 한다는 대안이 나왔습니다.
하지만 루트 파일 시스템을 pivot하면 호스트에 영향이 간다는 단점이 있습니다.
Namespace
그래서.. 네임스페이스라는 개념이 나왔습니다.
프로세스의 환경을 격리하기 위해서 마운트 환경만 격리한다는 아이디어가 나온 것입니다.
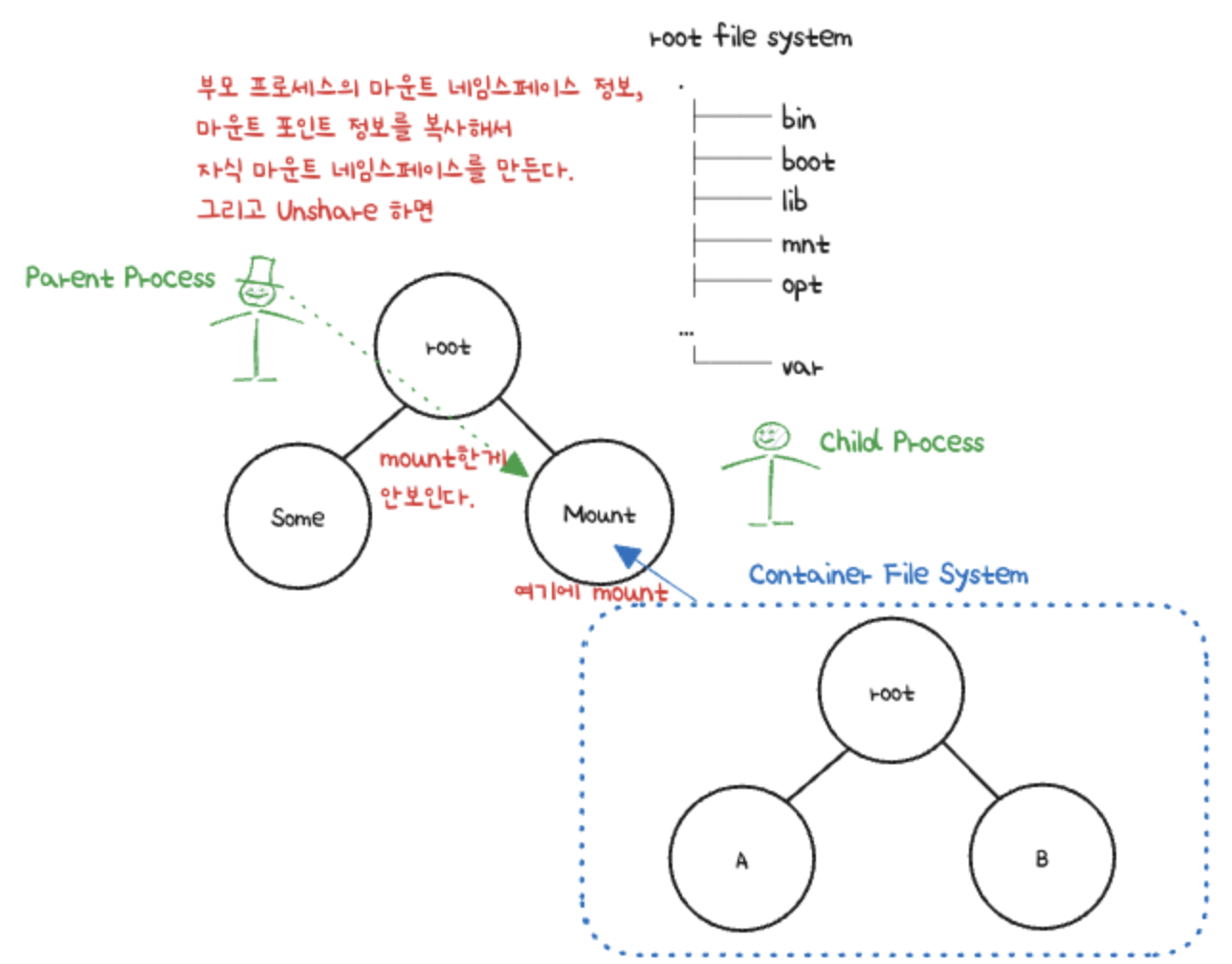
그림으로 그려 봤는데, 이런 느낌인것 같습니다.
실제로 위 그림을 위한 실습을 해보겠습니다.
격리를 하고 격리된 상태에서 실행할 명령어를 줍니다.
마운트 네임스페이스를 unshare해도 아래와 같이 같다.
부모 프로세스의 마운트 네임스페이스 정보를 복사해서 자식 네임스페이스를 만드므로 처음에는 똑같습니다.
# unshare 하고 df 로 확인
sudo unshare --mount /bin/sh
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 48G 2.8G 45G 6% /
...
# 그리고 unshare 안하고 host에서
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 48G 2.8G 45G 6% /
...-t 옵션은 type으로 tmpfs는 temporary file system이라는 메모리 기반의 파일 시스템입니다.
device는 none
부착 위치는 new_root
아래와 같이하면 호스트에서는 마운트 네임스페이스가 보이지 않습니다.
마운트 네임스페이스를 격리했기 때문입니다.
# unshare 된 위치에서
mkdir new_root
mount -t tmpfs none new_root
mount | grep new_root
none on /tmp/new_root type tmpfs (rw,relatime,inode64)
cp -r myroot/* new_root
tree
.
└── usr
└── lib
└── x86_64-linux-gnu
└── liblz4.so.1
# host에서
mount | grep new_root
# 안보인다.
tree new_root
# 안보인다.이제 루트 파일 시스템에 갈 영향에 대한 걱정없이 pivot_root를 해볼 수 있습니다.
# 격리된 마운트 네임스페이스에서
mkdir new_root/put_old
cd new_root
ls
bin lib lib64 put_old usr위와 같은 상태에서 루트 파일 시스템을 바꿔봅니다.
# 마운트 된 네임스페이스에서
# 새로운 루트 파일 시스템이 될 위치에서
# 현재 디렉토리가 새로운 루트파일 시스템이 될 것이다 "."
# 그리고 기존 루트 파일시스템은 put_old로
pivot_root . put_old
cd /
ls /
bin lib lib64 put_old usr
# host에서
ls /
bin dev lib lost+found opt run snap tmp
bin.usr-is-merged etc lib.usr-is-merged media proc sbin srv usr
boot home lib64 mnt root sbin.usr-is-merged sys var호스트와 다른 것을 알 수 있습니다.
그렇다면 그 상태에서 put_old 를 조회해보면 ?
# 격리된 공간에서
cd put_old
ls
bin dev lib lost+found opt run snap tmp
bin.usr-is-merged etc lib.usr-is-merged media proc sbin srv usr
boot home lib64 mnt root sbin.usr-is-merged sys var호스트의 루트 파일 시스템들이 여기에서 볼 수 있는 것을 알 수 있습니다.
이렇게 하면 탈옥이 된다는 chroot의 단점을 상쇄할 수 있습니다.
Container 격리에 사용되는 기술들 2. 매번 이렇게 똑같이 격리하면 필요없는 중복 파일이 많아지니 이 문제를 해결하자, 오버레이 파일 시스템
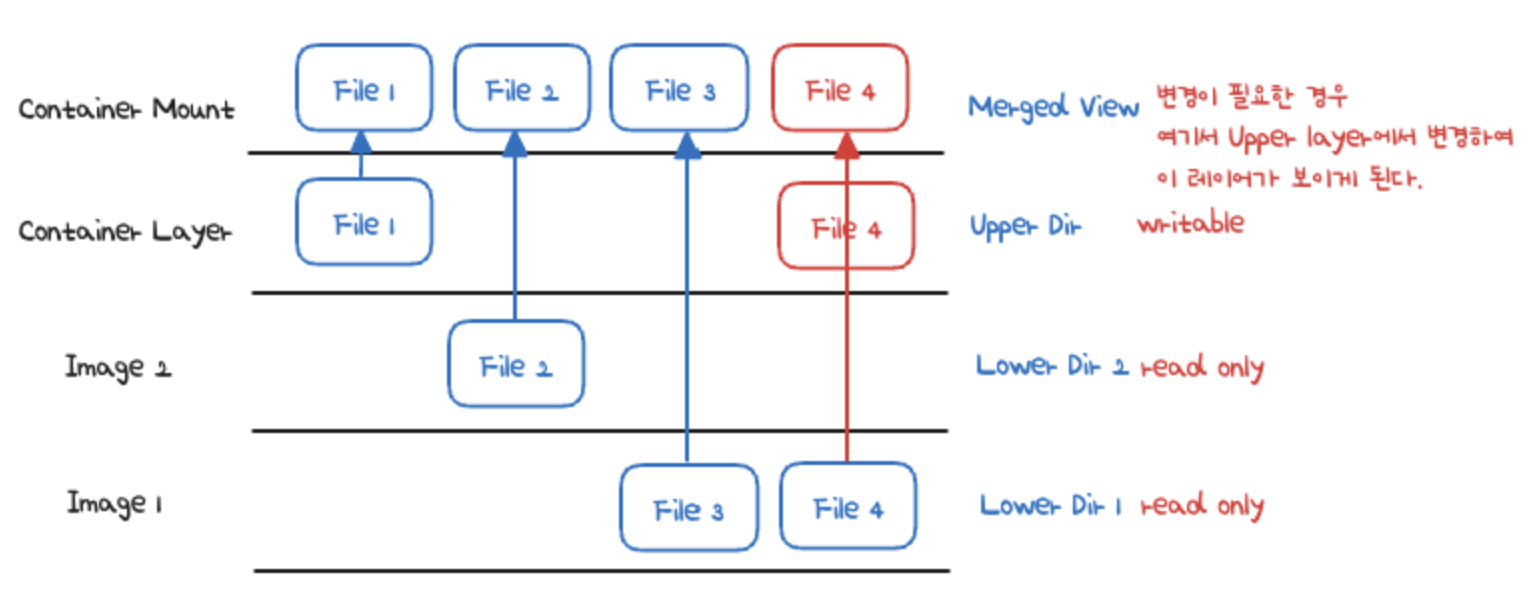
오버레이 파일 시스템을 도식으로 그려보면 위와 같이 됩니다.
이제 실습을 위해
파일을 준비합니다.
mkdir tools
mkdir -p tools/usr/bin
cp /usr/bin/which tools/usr/bin
mkdir -p tools/{bin,lib64,lib/x86_64-linux-gnu}
cp /bin/rm tools/bin/
cp /lib/x86_64-linux-gnu/libc.so.6 tools/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 tools/lib64/
tree tools/
tools/
├── bin
│ └── rm
├── lib
│ └── x86_64-linux-gnu
│ └── libc.so.6
├── lib64
│ └── ld-linux-x86-64.so.2
└── usr
└── bin
└── which
오버레이 마운트를 준비합니다.
mkdir -p rootfs/{container,work,merge}
sudo mount -t overlay overlay -o lowerdir=tools:myroot,upperdir=rootfs/container,workdir=rootfs/work rootfs/merge위 도식대로라면,
container는 upper directory
merge는 통합 뷰 : 실제 오버레이 마운트 되는 포인트
work는 atomic한 write 를 보장하기 위해 존재하는 디렉토리입니다.
아래를 실행해보면 rootfs/merge는 기존에 빈 디렉토리였지만
이제 파일들이 존재하는 것을 볼 수 있습니다.
cd rootfs
ls
container merge work
tree -L 2
.
├── container
├── merge
│ ├── bin
│ ├── lib
│ ├── lib64
│ └── usr
└── work
└── work그리고 추가 변경된 rm 과 비교해보면
tree -L 2 myroot
myroot
├── bin
│ ├── ls
│ └── sh
├── lib
│ └── x86_64-linux-gnu
└── lib64
└── ld-linux-x86-64.so.2
tree -L 2 my_root/merge/{bin,usr}
merge/bin
├── ls
├── rm
└── sh
merge/usr
├── bin
│ └── which
└── lib
└── x86_64-linux-gnu오버레이 마운트가 되어서 tools에서 복사한 rm, which가 보이는 것을 알 수 있습니다.
Container 격리에 사용되는 기술들 3. Namespace
Namespace
네임스페이스의 특징은 다음과 같습니다.
- 모든 프로세스는 타입별로 네임스페이스에 속합니다.
- 자식 프로세스는 부모의 네임스페이스를 상속합니다.
unshare
-M, --mount
-U, --uts
-I, --ipc
-P, --pid
-N, --net
-U, --user위 네임스페이스 종류의 역사는 위에서 언급한 도식에 나와있습니다.
네임스페이스 확인 방법
아래와 같이 inode 값으로 현재 프로세스가 어떤 네임스페이스에 속해있는지 종류별로 알 수 있습니다.
ls -al /proc/$$/ns
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 net -> 'net:[4026531840]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 time -> 'time:[4026531834]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 user -> 'user:[4026531837]'
lrwxrwxrwx 1 ubuntu ubuntu 0 Aug 31 13:48 uts -> 'uts:[4026531838]'또한 readlink 심볼릭 링크를 읽어서 바로 inode 값을 확인할 수도 있습니다.
readlink /proc/$$/ns/mnt
mnt:[4026531841]list namespace라는 커맨드도 따로 있습니다.
lsns -p 1
NS TYPE NPROCS PID USER COMMAND
4026531834 time 115 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531835 cgroup 114 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531836 pid 114 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531837 user 115 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531838 uts 108 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531839 ipc 114 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531840 net 114 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531841 mnt 104 1 root /usr/lib/systemd/systemd --system --deserialize=39
lsns -p 1 -t mnt
NS TYPE NPROCS PID USER COMMAND
4026531841 mnt 104 1 root /usr/lib/systemd/systemd --system --deserialize=39Mount Namespace
아래 처럼 해보면 각 namespace들을 isoloation 해볼 수 있습니다.
마운트 네임스페이스의 경우입니다.
unshare -m
lsns -p $$
NS TYPE NPROCS PID USER COMMAND
4026531834 time 117 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531835 cgroup 116 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531836 pid 116 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531837 user 117 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531838 uts 110 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531839 ipc 116 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026531840 net 116 1 root /usr/lib/systemd/systemd --system --deserialize=39
4026532291 mnt 2 22163 root -bashUTS Namespace
UTS, Unix Time Sharing
호스트명, 도메인명을 격리합니다.
IPC Namespace
Inter Process Communication
프로세스간 통신
share memory나 pipe나 message queue
IPC 네임스페이스를 공유하는 프로세스끼리만 IPC 통신을 할 수 있습니다.
PID Namespace
Process ID 넘버 스페이스를 격리
부모 네임스페이스가 있고 그 위에 올라가는 자식 프로세스 중첩 구조를 가집니다.
그리고 부모에서는 다 보이고, 자식 네임스페이스에는 그만의 별도 PID 값도 있습니다.
컨테이너의 경우 PID 네임스페이스를 unshare 할때 자식프로세스로 fork를 하여
실행 하고자하는 커맨드, 프로세스를 PID 네임스페이스의 PID 1 로 만듭니다.
그래서 얘가 죽으면 컨테이너가 종료됩니다.
# pid 네임스페이스를 격리하고
unshare -fp --mount-proc /bin/sh
ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 15:26 pts/1 00:00:00 /bin/sh
root 2 1 0 15:27 pts/1 00:00:00 ps -ef
lsns -t pid -p 1
NS TYPE NPROCS PID USER COMMAND
4026532292 pid 2 1 root /bin/sh
# host에서
ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Aug30 ? 00:00:08 /usr/lib/systemd/systemd --system --deseriali
root 2 0 0 Aug30 ? 00:00:00 [kthreadd]
root 3 2 0 Aug30 ? 00:00:00 [pool_workqueue_release]
# unshare의 자식프로세스로 /bin/sh 이 보입니다.
ps -ef | grep "/bin/sh"
root 22262 21680 0 15:26 pts/3 00:00:00 sudo unshare -fp --mount-proc /bin/sh
root 22263 22262 0 15:26 pts/1 00:00:00 sudo unshare -fp --mount-proc /bin/sh
root 22264 22263 0 15:26 pts/1 00:00:00 unshare -fp --mount-proc /bin/sh
root 22265 22264 0 15:26 pts/1 00:00:00 /bin/sh
ubuntu 22271 21738 0 15:28 pts/4 00:00:00 grep --color=auto /bin/sh
lsns -t pid -p 22265
NS TYPE NPROCS PID USER COMMAND
4026532292 pid 1 22265 root /bin/sh
위와같이 lsns 로 같은 프로세스인것을 확인할 수 있습니다.
Network Namespace
네트워크 네임스페이스는 컨테이너의 네트워크를 호스트와 격리합니다.
네트워크 가상화를 해서 가상 인터페이스 장치를 사용할 수 있습니다.
네트워크 가상 장치 : veth, bridge, vxlan
으로서 물리 장치처럼 취급해서 꽂을 수 있습니다.
이제 veth간 연결 테스트를 해봅니다.
ip link add veth0 type veth peer name veth1
ip link
...
11: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether d2:18:99:e7:79:0a brd ff:ff:ff:ff:ff:ff
12: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6a:d2:8d:79:a9:c4 brd ff:ff:ff:ff:ff:ff위를 그림으로 표현하면 아래와 같습니다.

이제 네임스페이스를 하나씩 추가합니다.
그리고 여기에 아까 있었던 veth0, veth1을 꽂습니다.
veth는 물리장치처럼 자유롭게 network namespace에 꽂을 수 있다고 했습니다.
# network namespace 생성
ip netns add RED
ip netns add BLUE
# veth 부착
ip link set veth0 netns RED
ip link set veth1 netns BLUE
# veth 가동
ip netns exec RED ip link set veth0 up
ip netns exec BLUE ip link set veth1 up
# ip 부여
ip netns exec RED ip addr add 11.11.11.2/24 dev veth0
ip netns exec BLUE ip addr add 11.11.11.3/24 dev veth1위 내용을 그림으로 표현하면 아래와 같습니다.
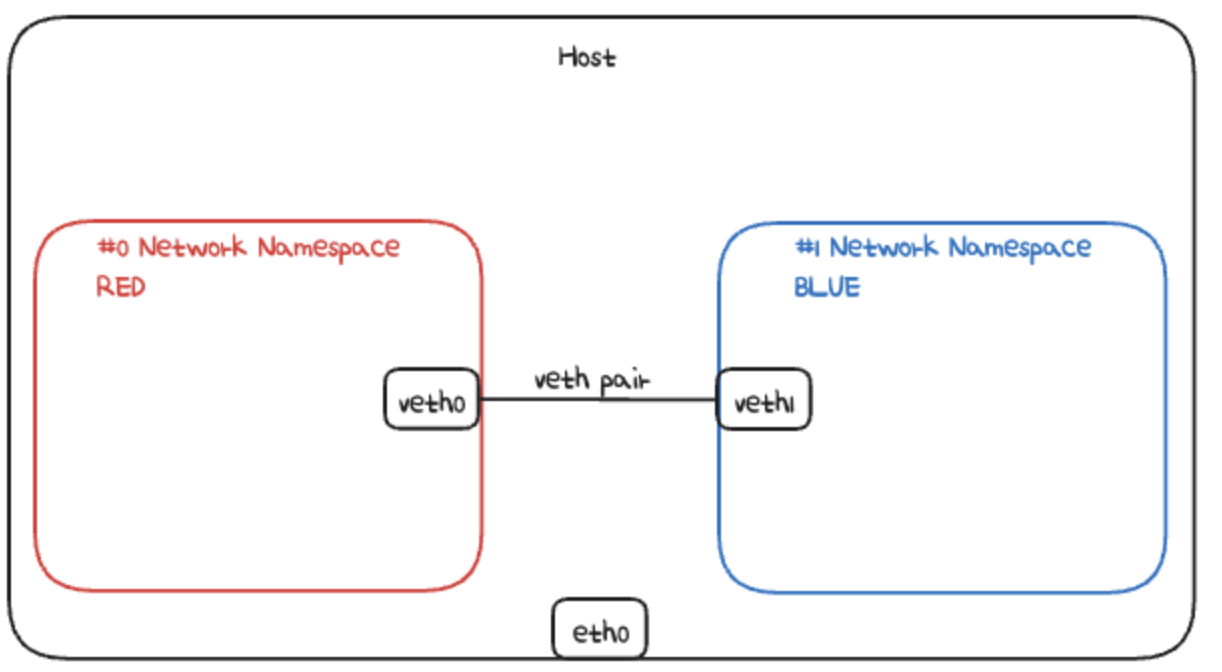
이제 각 네임스페이스에 진입해서 테스트를 해볼 수 있습니다.
ls /var/run/netns
BLUE RED
nsenter --net=/var/run/netns/RED
# RED에 진입하면
# 인터페이스가 2개만 보입니다.loopback, veth0
ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
12: veth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 6a:d2:8d:79:a9:c4 brd ff:ff:ff:ff:ff:ff link-netns BLUE
inet 11.11.11.2/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::68d2:8dff:fe79:a9c4/64 scope link
valid_lft forever preferred_lft forever
ip route
11.11.11.0/24 dev veth0 proto kernel scope link src 11.11.11.2
# BLUE로 데이터 전송
ping 11.11.11.3
PING 11.11.11.3 (11.11.11.3) 56(84) bytes of data.
64 bytes from 11.11.11.3: icmp_seq=1 ttl=64 time=0.031 ms
# BLUE에서 데이터 받기
tcpdump -li veth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
15:50:26.418519 IP 11.11.11.2 > 11.11.11.3: ICMP echo request, id 22441, seq 12, length 64
15:50:26.418534 IP 11.11.11.3 > 11.11.11.2: ICMP echo reply, id 22441, seq 12, length 64
ip netns del RED
ip netns del BLUEUSER Namespace
UID/GID 넘버스페이스를 격리하고, 컨테이너의 루트 권한 문제를 해결합니다.
UID/GID 를 remap 할 수 있는데, 부모 user namespace에서의 uid1000을 자식 user namespace에서 uid 0으로 remap하는 방식입니다.
그래서 host에서는 아니지만, 컨테이너 안에서만 root 권한으로 보이게 할 수 있습니다.
Container 격리에 사용되는 기술들 4. Cgroups
Cgroups은 Control Groups를 의미하며, 컨테이너 별로 자원을 분배하고 limit 내에서 운용할 수 있습니다.
cpu, memory 같은 시스템 자원을 group으로 묶어서 프로세스를 해당 그룹에 포함시킵니다.
또한 이 자원 할당과 제어는 파일 시스템으로 제공하며 cgroup namespace로 제어할 수 있습니다.
관련 실습을 해보겠습니다.
sudo -Es
apt-get install -y cgroup-tools
apt-get install -y stress그리고 부하를 줘봅니다.
stress -c 1
stress: info: [22925] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22926 root 20 0 3620 384 384 R 100.0 0.0 0:36.58 stress그리고 cgroup을 생성해서 나눠줍니다.
cgcreate -a root -g cpu:mycgroup
tree /sys/fs/cgroup/mycgroup -L 1
/sys/fs/cgroup/mycgroup
├── cgroup.controllers
├── cgroup.events
├── cgroup.freeze
├── cgroup.kill
├── cgroup.max.depth
├── cgroup.max.descendants
├── cgroup.pressure
...cgroup v2에 대한 변경사항이 있습니다.
cpu.cfs_period_us및cpu.cfs_quota_us에 해당하는cgroups-v2파일은cpu.max파일입니다.cpu.max파일은cpu컨트롤러를 통해 사용할 수 있습니다.
30000으로 제어해봅니다.
100000이 기준이니까 30%로 제약한겁니다.
echo "30000 100000" > /sys/fs/cgroup/mycgroup/cpu.max이제 부하를 주면 커널이 cgroup에 맞게 쓰로틀링을 걸어줍니다.
cpu사용률을 30%만 쓰는 모습을 볼 수 있습니다.
cgexec -g cpu:mycgroup stress -c 1
stress: info: [23047] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
23048 root 20 0 3620 384 384 R 30.2 0.0 0:05.25 stress마무리
이렇게 쿠버네티스의 모든 기본이 되는 컨테이너 격리에 대한 내용을 공부해봤습니다.
잊혀진 기초나 몰랐던 내용까지 함께 공부하고 나니 왠지 쿠버네티스 네트워크 심화에 대한 자신감이 생기는 기분이네요.
Reference
널널한 개발자님 유튜브
Overview | Kubernetes
이게 돼요? 도커 없이 컨테이너 만들기 / if(kakao)2022 - YouTube
x.com
'Kubernetes' 카테고리의 다른 글
| Container Runtime과 CRI, 그리고 Containerd 알아보기 (0) | 2024.09.08 |
|---|---|
| Kind와 OrbStack를 사용해서 쉽게 Local에서 Kubernetes 사용하기 (2) | 2024.09.05 |
| GitOps : Tekton, ArgoCD 로 CI/CD 하기 (0) | 2023.03.24 |
| [스터디] Kubernetes Container Networking 정리 (0) | 2023.03.18 |
| Kubernetes cluster에 Locust를 올려서 분산 부하 테스트한 후기 (4) | 2023.01.08 |