글 작성일: 2021.10.03
쿠버네티스에서 올라가 있는 application pod에서 사용하고 있는 sidecar의 요구 자원을 줄일 수 있는 지 확인하기 위해서 해당 Pod에 부하를 걸어 볼 필요성이 생겼다.
sidecar에 기본 설정된 CPU limits Core가 높게 설정되어 있는데,
만들고 있는 application의 ui에서 해당 네임스페이스의 limits를 기반으로 모델 배포관리를 하기 때문에 이런 상황이 된 것이다.
이 떄문에 부하 테스트 도구를 찾아보게 되었다.
Locust, JMeter, LoadRunner, SilkPerformer 등의 이름이 보였고 제각기 장단점이 있겠지만 그 중 Locust를 골랐다.
Locust의 장점은 다음과 같다.
- 시나리오를 파이썬 스크립트로 작성할 수 있어서 편하다.
- 테스트 시나리오가 스크립트로 되어 있어서, 소스코드로 관리가능하다.
- 필요한 서버 리소스가 작아서 작은 크기의 부하 테스트 서버로 테스트 가능하다.
사용 설명
설치방법
파이썬 3.6 이상이 요구 된다.
현재 버전은 2.2.1이다.
pip3 install locust
locust -V
> locust 2.2.1아래 내용은 Locust Documentation의 Writing a locustfile의 내용이다.
Writing a locustfile
# example locustfile.py
import time
from locust import HttpUser, task, between
class LoadTestUser(HttpUser):
wait_time = between(1, 2.5)
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_items(self):
for item_id in range(10):
self.client.get(f"/item?id={item_id}", name="/item")
time.sleep(1)
def on_start(self):
self.client.post("/login", json={"username":"foo", "password":"bar"})import time
from locust import HttpUser, task, betweenlocust 파일은 단순한 파이썬 모듈이라서 다른 파일이나 패키지에서 임포트해올 수 있다.
class LoadTestUser(HttpUser):이 예제에서는 User Class를 정의한다. HttpUser를 상속하는데,
각 유저에 client attribute를 제공한다.
HttpSession의 인스턴스이고 HTTP request를 부하 테스트를 원하는 타겟 시스템에 던질 수 있다.
테스트가 시작하면 Locust는 시뮬레이션하는 유저들의 클래스 인스턴스를 생성한다. 그리고 그 "각 유저는" "green gevent thread"를 running 한다.
wait_time = between(1, 2.5) 이 wait_time 은 테스트를 시뮬레이션하는 유저들이 각 태스크 사이에 대기하는 시간을 말한다.
Locust는 테스팅 시나리오를 수행하는 running user들을 설정에 따라 지속 생성하는데,
모든 running user들에게 Locust는 greenlet(micro-thread)를 생성한다.
그 greelet이 method들을 call 한다.
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_items(self):
...두 개의 method가 @task로 decorated 되는 모습을 볼 수 있다.
그 중 하나는 higher weight를 부여받았다, 이 경우 (3).
두 개의 Task가 정의되어 있는데, 이 태스크들은 랜덤으로 실행된다.
이 케이스에서 두 개의 메서드가 있으니, 랜덤으로 실행되지만 다른 weight로 실행이 되는 것이다.
말하자면 view_items method는 실행 될 확률이 3배인 것이다.
태스크가 실행을 끝내면 각 유저는 위에서 정의된 대로 1초에서 2.5초 사이를 쉰다.
쉰 다음에 유저는 다른 태스크를 잡고 이후 반복된다.
@task로 decorated된 method만 유저의 실행 대상이 된다.
그래서 다른 helper method를 정의해도 된다.
self.client.get("/hello")self.client attribute는 HTTP call이 Locust에 의해 logging 이 되도록 만들어준다.
request, response validating에 대해서는 https://docs.locust.io/en/stable/writing-a-locustfile.html#using-the-http-client 확인
@task(3)
def view_items(self):
for item_id in range(10)
self.client.get(f"/item?id={item_id}", name="/item")
time.sleep(1)view_items 태스크는 variable query parameter를 이용해서 10개의 다른 URL을 로드한다.
Locust의 통계가 URL아래에 그룹화되므로 Locust의 통계에서 10개의 항목을 별도로 가져오지 않으려면 name parameter를 사용하여 "/item"이라는 항목 아래에 있는 모든 요청을 그룹화한다.
def on_start(self):
self.client.post("/login", json={"username":"foo", "password":"bar"})on_start method는 매 시뮬레이션 유저가 시작할 때 호출된다.
실행
locust -f 작성한파일.py실제 사용
매뉴얼에서 본 대로 실제 테스트를 위한 코드를 작성해봤다.
대충 아래와 같은 식이다.
@task
def test(self):
token = "XXX"
url = "XXX"
headers = {'Content-Type': 'application/json; charset=utf-8', "Authorization" : "Bearer " + token}
api = "XXX""
payload = { XXX }
res = requests.post(url, headers = headers, data = json.dumps(payload))locust 파일을 실행하고 안내되는 local ip로 들어가면 아래와 같은 화면을 볼 수 있다.
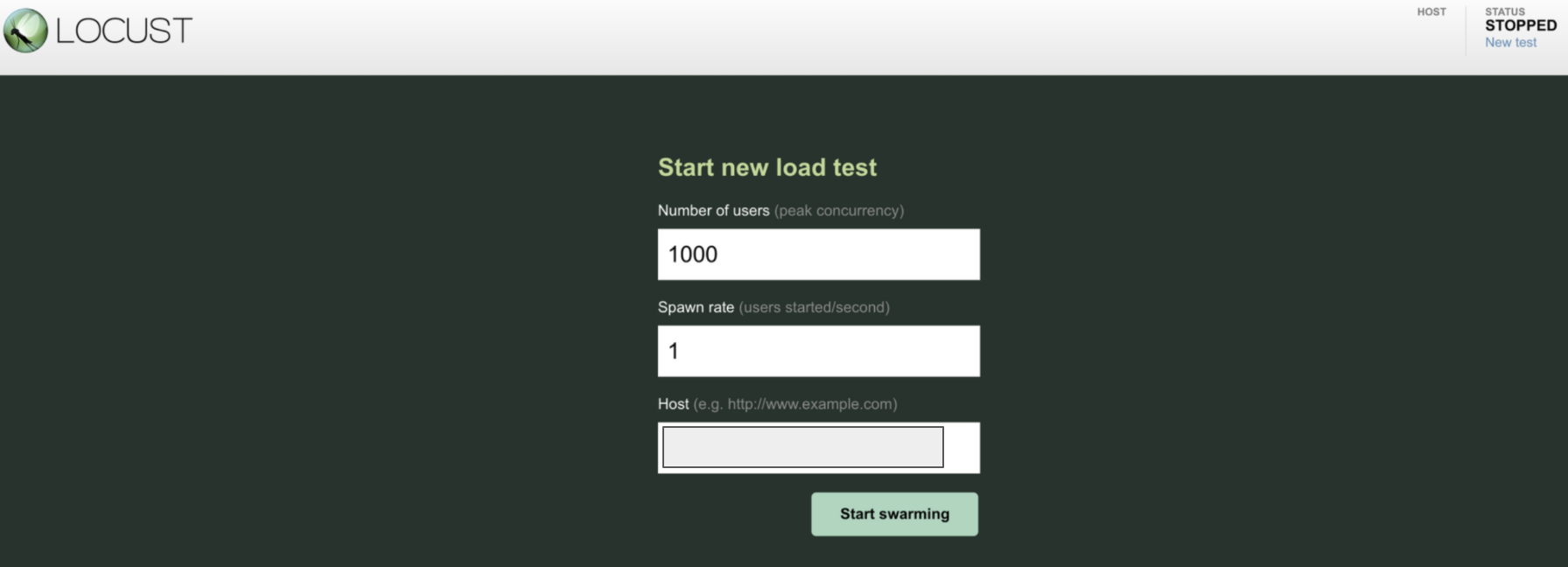

그러면 이런 식으로 테스트에 참여하는 유저의 숫자가 늘어나고


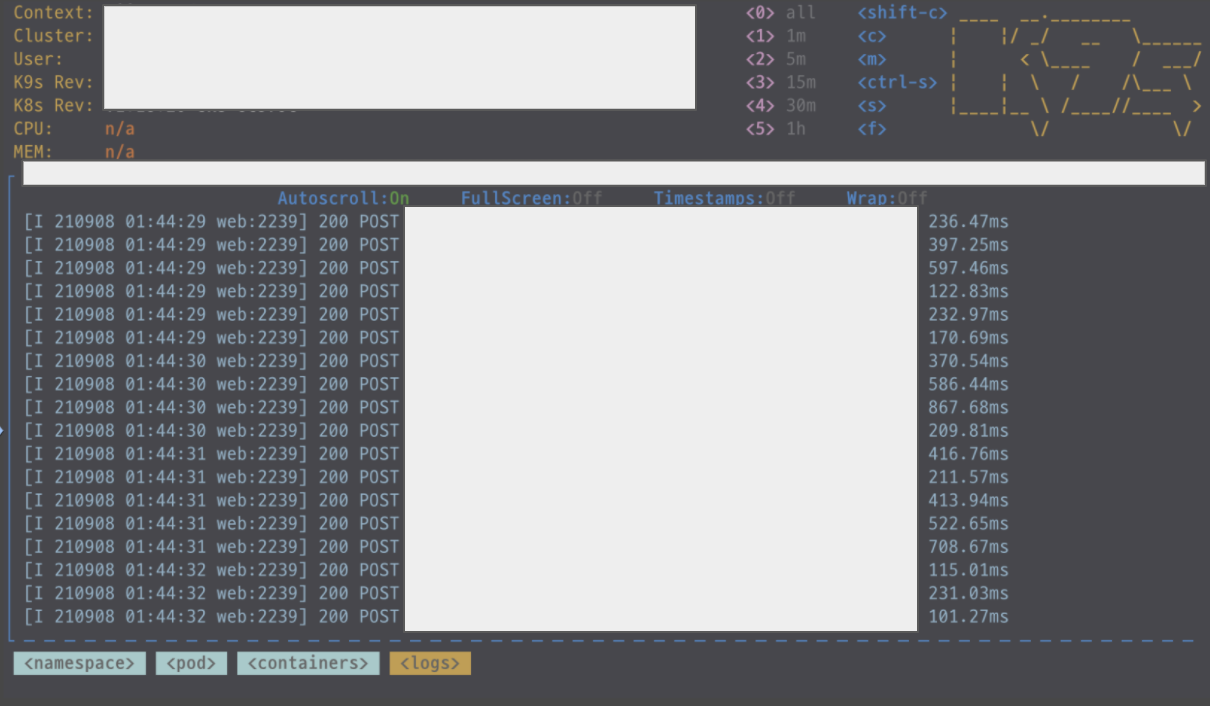
그리고 아래와 같이 쿠버네티스의 app pod에 요청이 제대로 들어오고 있는 모습을 확인할 수 있다.

테스트에 대한 결과 차트도 시각화된 형태로 볼 수 있다.

해당 내용들을 담은 전체 결과 보고서도 따로 html 파일로 다운로드 받을 수 있게 되어있다.
Reference
'IT' 카테고리의 다른 글
| IP로 Harbor HTTPS Access 가능하게 설정하며 과정 다시 되짚어보기 (0) | 2022.01.05 |
|---|